|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
Участники:
Лоскутов Алексей
Плетнёва Софья
Лауринавичюте Анна
Ларин Вова
Иванов Илья
Фанасков Роман
Суровцев-Бутов Андрей
 На проекте
На проекте

 На отчёте проекта
На отчёте проекта
 Стенд проекта
Стенд проекта
Отчет группы программистов проекта
Авторы:
Суровцев-Бутов Андрей
Иванов Илья
Руководитель проекта:
Граф Александр Воронцов
Город Пущино-на-Оке
2003
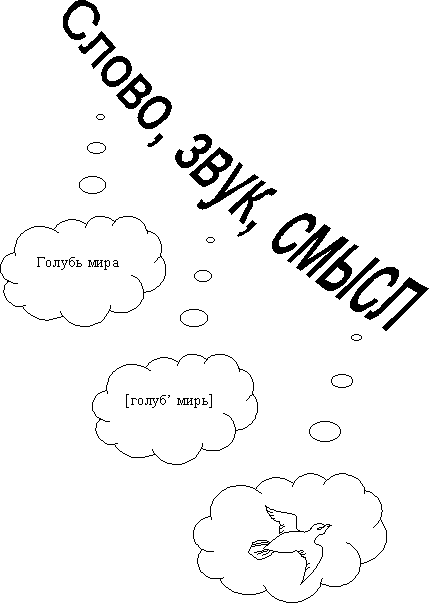
Известно, что образ, возникающий в сознании в результате прослушивания некого звукового фрагмента, определяется не только лексическим значением этого фрагмента, но и звучанием.
Целью нашего проекта являлось выяснение связи между фонетической транскрипцией произносимого слова – звуком, издаваемым говорящим, и эмоциональной характеристикой данного слова – реакцией слушателя.
Мы решили ограничиться следующими свойствами звука: характером вызываемого образа (шкала хороший-плохой), его силой (сильный-слабый), скоростью (быстрый-медленный), температурой (теплый-холодный), размером (большой-маленький).
Для начала мы решили определить заданные характеристики для каждого звука в отдельности. Наши люди из проекта провели небольшое социологическое исследование для выполнения этой задачи. Сравнив результаты оного с результатами аналогичного более масштабного эксперимента, мы пришли к выводу, что такие характеристики действительно имеют место быть рассмотренными.
Перед нами встала следующая проблема – перейти от свойств звуков к свойствам слов. Здесь мы решили руководствоваться не только элементарными характеристиками звуков – мы решили также учесть редкость рассматриваемых звуков: чем реже встречается звук, тем больше эмоциональная окраска слова зависит от него.
Для того чтобы анализировать отдельные слова, а тем более составленные из них тексты, нам было необходимо сделать соответствующие программы для автоматизации вычислений с числовыми значениями букв.
{ Здесь важно заметить, что наша программа смогла сильно ускорить ход нашей работы на проекте.}
При написании нашей программы мы использовали следующий алгоритм: текст мы разбиваем на слова, по каждому из которых рассчитывается характеристика, а после этого берётся средние характеристики всех слов текста. Слово мы разбиваем на звуки, учитывая частоту их появления по отношению к другим словам данного слова, рассчитываем коэффициент влияния звука в слове таким образом:
|
Далее мы мультипликативно совмещаем характеристику каждого звука и его коэффициент и суммируем их.
|
где tm – одна из характеристик слова, ti – соотв. характеристика i-той буквы этого слова, n – число букв в слове.
Далее, зная характеристики каждого слова мы таким образом мы подсчитываем средние характеристики всего текста:
|
где t – какая-либо характеристика текста в целом, ti – эта характеристика i-того слова, m – число слов в тексте.
В процессе работы над основной программой нашего проекта мы создали ещё несколько прог, которые поспособствовали развитию нашего проекта, т.е. помогли другим, производившимся здесь исследованиям.
"Длина" – рассчитывает "расстояние" между всеми звуками в системе наших характеристик и выводящей результаты в виде таблицы.
"Богослов" – сравнивает частоту появления звуков в данном тексте со стандартной средней частотой и наглядно выводит результаты.
"Звездочёт" – помогает быстрому чтению различных русскоязычных текстов. Переводит все литеры в верхний регистр.
"Игумен" – анализирует вывод главной программы и вычисляет средние характеристики всех предварительно проанализированных файлов.