|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
|
| ||
Отчет о выполненной работе проекта
 На отчёте проекта
На отчёте проекта
 Стенд проекта
Стенд проекта
Все началось с того, что мы (Люда Петрова, Таня Курятникова, Андрей Лесков, Сергей Попов) решили разобраться, что же нам предстоит делать. А предстояло нам делать следующее: научить компьютер (кто-то говорил, что он умный...) различать человеческие лица.
Сперва задача была предельно простой (нам так показалось): на бумажке написать алгоритм обработки картинок с лицами. Потом с каждой минутой всем становилось яснее и яснее что... ничего так сразу не получится. К концу первого рабочего дня мы сформулировали некоторые законы, по которым компьютеру было бы легче обрабатывать множество картинок.
Вот некоторые из них:
Уменьшить картинку с изображением Вашего (или нашего) лица до приемлемых размеров (128 на 128 точек (примерно 5.5 на 5.5 см)).
Вытащить из картинки только изображение лица (желто-коричневые тона), удалив при этом фон вокруг лица.
Преобразовать цвета полученного в пункте 2 изображения в оттенки серого (синего, красного - кому как нравится).
Упростить цвета полученного в предыдущем пункте изображения до трех-четырех цветов.

На второй день у нас появилась почти работающая программа по вытаскиванию желто-коричневых оттенков из фотки. После ее усовершенствования программа стала вполне уверенно рисовать обработанные картинки:
Однако ж, подобранные параметры для обработки одного лица никак не хотели подходить для качественной обработки другого. Например, программа, настроенная на лицо Люды совсем не желала обрабатывать фотку с моим (чьим?) лицом... В итоге день был потрачен на подбор универсальных параметров для разных типов лиц.
Кстати, перед тем как разработать метод выделения желтой составляющей рисунка нам пришлось разобраться в палитрах, цветовых кубиках и всем прочем. Любой цвет на компьютере можно закодировать тремя числами. Как мы знаем, цвет (свет) можно свести к трем базовым цветам: красному (R), зеленому (G) и синему (B) (ИСН наверняка сказал бы лучше и умнее). Вот пример цветового кубика:
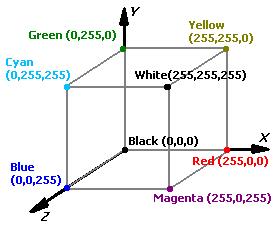
Так как мы ищем на рисунке точки, имеющие цвет лица (коричнево-желтые), то нам понадобятся грани, которые имеют вершинуYellow. Исследуя координаты кубика, мы нашли те значения RGB, при которых на фотографиях остается только лицо. Одна из нерешенных проблем - это фон фотки. Если он красный или желтый, то программа дает сбои. Но в скором времени (преступники, берегитесь) это проблема будет решена.
Весь третий день ушел на установку программного обеспечения (Visual Studio 6 T, C++ Builder T) и освоения C++. Так как ведущие проекта избрали язык программирования C++ основным, то немало времени было потрачено на его начальное изучение учениками. Сами ученики особо не противились изучению нового инструмента (ученье - свет, а неученье - тьма). В этот же день мы обнаружили, что голубой составляющей (B) в лицах почти нет, откуда был сделан вывод о том, что фотографироваться надо на голубом (ну, на худой конец, синем) фоне. В этом случае этот многострадальный фон можно будет удалить очень легко и безболезненно.
На четвертые сутки функционирования проекта дела наконец (пока) пошли в гору: появились реальные идеи осуществления 3 и 4 пунктов начальной фазы работы (хитрость - сестра шифровщика). Мы сошлись на том, что изображение, нарисованное в серых тонах, необходимо корректировать, придавая ему больше контраста. Эта идея была воплощена на компьютере через десять минут. Далее последовал долгий (а может, нам показалось) поиск наилучшего сочетания яркости и контраста. Затем перед программистами встал вопрос, как сделать картинку не просто серой, а еще и уменьшить количество отображаемых на ней цветов до 4 (на сегодняшний день это число цветов является оптимальным: черный и три оттенка серого). Конечно (точнее, как всегда) мнения по поводу преобразования лица в четырехцветный формат разошлись. Вначале было предложено два алгоритма:
Простое разделение всех цветов (на рисунке в оттенках серого их может быть до 255) на 4 промежутка.
Нахождение наиболее яркой точки рисунка и деление на 4 цветовых промежутка относительно ее.

Ниже представлен результат обработки изображения с помощью первого алгоритма:
Как в итоге выяснилось, ни первый, ни второй алгоритм не смогли удовлетворить наши потребности, так как большинство цветов превращаются в какой-нибудь один. Поэтому был предложен координально новый принцип обесцвечивания картинки. Этот метод состоит в нахождении среднего оттенка изображения. Затем по нему все цвета рисунка делятся на две или четыре (от желаемого количества цветов) группы, что позволяет фотографию привести к двух- или четырехцветному виду. Этот принцип работает лучше двух первых, потому что в конечном итоге получается контрастная картинка, на которой четко видны все четыре цвета.
Далее идеи рождались не по дням, а по часам; поэтому мы потеряли счет дням, и ниже идеи представлены в порядке их появления по часам.
Взяли несколько точек в середине картинки усреднили значения их цветов (ведь именно в этой области картинки находится лицо). Затем программа, двигаясь из центра по направлению к краям картинки, постоянно сравнивает цвет текущего пикселя с образцом цвета лица. Если по R, G или B цвет пикселя отличается на определенное число (например, на 70), то программа считает это началом фона и отсекает его от лица. После этого остается прямоугольник с лицом.
Был реализован алгоритм умного "отчернобеливания". Но, посмотрев на результаты, мы быстренько поняли, что ничего нам это не даст.  Да, после обработки ясно видны черты лица, глаза, но, обработав две разные фотки с одним и тем же человеком, стало понятно, что при наложении двух этих фоток точки абсолютно не совпадают. Кроме того, целостность изображения резко теряется, что делает невозможным дальнейшее исследование. Таким образом, этот 'продвинутый' метод годится только для получения красивых черно-белых фоток, но не для сравнивания:
Да, после обработки ясно видны черты лица, глаза, но, обработав две разные фотки с одним и тем же человеком, стало понятно, что при наложении двух этих фоток точки абсолютно не совпадают. Кроме того, целостность изображения резко теряется, что делает невозможным дальнейшее исследование. Таким образом, этот 'продвинутый' метод годится только для получения красивых черно-белых фоток, но не для сравнивания:
Идея заключалась в том, что, приводя точку к черному или белому цвету, мы исходим не только из цвета самой точки, но также и из цветов нескольких точек окрестности этой точки. Мы взяли окрестность в 4 точки: сама точка - координаты (х, у) и ее соседи: (х+1,у), (х,у+1), (х+1,у+1). Мы считаем средний цвет этой окрестности и его округляем до черного или белого. Так идем по всей картинке и получаем в результате черно-белую картинку с визуально различимыми, но довольно раздробленными чертами.
Пожалуй, на сегодняшний момент самый приоритетный, хотя и требует доработок. Основная идея метода состоит в том, чтобы при обработке картинки количество пикселей того или иного цвета не имело значения. Теперь компьютер ищет действительно средний цвет, а не забивает на одиноко стоящие точки на монотонном фоне. Требуется корректировка при начальной переработке картинки в градации серого, над чем сейчас и занимаемся. Наша основная цель подготовить для Андрея Лескова этот алгоритм отрегулированным так, чтобы на любой фотке ясно проявлялись глаза. Вот пример одной из удачных фоток:
Теперь компьютер ищет действительно средний цвет, а не забивает на одиноко стоящие точки на монотонном фоне. Требуется корректировка при начальной переработке картинки в градации серого, над чем сейчас и занимаемся. Наша основная цель подготовить для Андрея Лескова этот алгоритм отрегулированным так, чтобы на любой фотке ясно проявлялись глаза. Вот пример одной из удачных фоток:
Тут есть несколько путей решения поставленной задачи.
Можно найти все возможные (в данной градации серого) яркости и посчитать среднюю из них. Но тут проблема такая, что если у нас, например, такой ряд яркостей: 1, 2, 3, 4, 34, 44, 47, 250, 252, 255, то средняя яркость будет 89 и получается, что только самые светлые тона будут белыми, а их может быть совсем мало. Это нехорошо. Поэтому мы подумали, что надо из этих чисел выбирать среднее не по среднему арифметическому, а по порядковому номеру. То есть числа необходимо отсортировать по возрастанию, а потом взять то из них, которое находится в середине этого ряда. В нашем случае это будет число 44, пятое по номеру. Таким образом, все цвета разделятся на две равные группы: количество светлых тонов будет приблизительно равно количеству темных. Но все же и у этого метода есть недостатки: середина ряда не всегда является оптимальным решением: картинка может получиться слишком темной. Поэтому приходится вводить коэффициент яркости: программа специально затемняет или осветляет исходную картинку, чтобы получить сбалансированную по яркости конечную. Получается так: чем больше затемняется обработанный исходник, тем светлее конечная черно-белая фотка. Ниже приведен образец отрегулированной по яркости фотки:
Поэтому приходится вводить коэффициент яркости: программа специально затемняет или осветляет исходную картинку, чтобы получить сбалансированную по яркости конечную. Получается так: чем больше затемняется обработанный исходник, тем светлее конечная черно-белая фотка. Ниже приведен образец отрегулированной по яркости фотки:
Кроме того, мы решили разделить все фотки на три группы: изображения с лицами светлых, средних и темных тонов. Идея заключается в том, что программа, настроенная хоть на одно лицо из какой-нибудь группы, хорошо работает на остальных лицах той же группы. Однако настройки для лиц светлого тона никогда не будут хорошо подходить под лица темного.
Просим детей, стариков, беременных женщин и слабонервных не читать главу 'Корректировка контраста', написанную ниже!!!
Теперь мы решили регулировать на картинке контраст.
Метод заключается в разделении 255 оттенков серого на три группы: например, от 0 до 128, от 128 до 192, от 192 до 255. Для первой группу мы яркость уменьшаем примерно на 20 процентов, для второй - вообще не изменяем, для третьей - поднимаем на 20 процентов.
Есть два принципа увеличения/уменьшения контраста:
Метод разрывной функции:
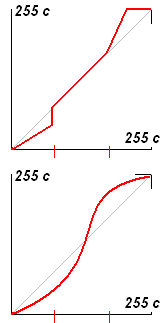
+ - очень быстро и просто (если все части - линейные функции)
- - получаются резкие перепады, так называемые 'Дыры':
( некоторые цвета пропадут в связи с округлением
(вертикальные линии на графике))
Метод непрерывной функции:
+ - нет 'Дыр', изменения цветов происходят плавно (цвета не
выпадают)
- - довольно медленно и сложно
На рисунке представлена функция, которая делает
темные точки более темными, а светлые точки более
светлыми, то есть увеличивает контрастность.
Надо бы для этого придумать саму функцию, такую чтобы:
Функция проходила через точки (0;0), (128;128), (255;255). (Ну или хотя бы близко к ним)
Выпуклость в промежутке от 0 до 128 была вниз, а в промежутке от 128 до 255 вверх.
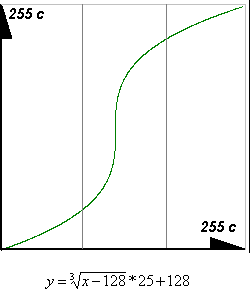
В конце концов мы подобрали подходящую по форме функцию. После некоторых домножений и сдвигов мы получили следующую формулу (ее график, построенный программой, приведен снизу):
После того, как контраст был прилично увеличен, кое-кому пришло в голову применить новый метод, названный методом Кластеров (Claster Method). Программа произвольно ставит воображаемый разделитель на координатной прямой, размеченной от 0 до 255 (от черного до белого, если кто не понимает). А затем компьютер считает по циклу сумму произведений номера цвета на количество точек с этим цветом с одной стороны от этого разделителя. Затем он проделывает то же самое (если вы что-то поняли из предыдущего предложения...) с другой стороны от разделителя. То есть в первой сумме оказываются все точки с цветами из промежутка от 0 до разделителя, а во второй, соответственно, сумма всех точек с цветами из промежутка от разделителя до 255. Пусть сумма в левой части будет называться Sum1, а в правой - Sum2. При этом количествовсех точек в левой части будет называться n1, а количество в правой - n2. Теперь разделим Sum1 на n1, таким образом, несколько уменьшив влияние количества того или иного цвета. Нетрудно доказать, что полученный результат будет принадлежать промежутку от 0 до разделителя. Так же разделим Sum2 на n2. А этот результат будет лежать в промежутке от разделителя до 255. Теперь посчитаем среднее арифметическое между полученными результатами. Если значение этого 'среднего' равно значению X координатной прямой цветов, где стоит разделитель, то программа берет полученный результат за средний цвет изображения; если нет - то разделитель сдвигается на точку, равную по значению 'среднему', и все повторяется (смотри начало абзаца) уже с новым разделителем. Программа обязательно завершится, потому что число точек конечно, а суммы, деленные на количество точек, в какой-то момент уравновесятся с обеих сторон. Уравновешение произойдет, так как разделитель будет "смещаться" в сторону с наибольшим "весом", то есть только в одну сторону.
 |  |
| Исходное изображение ископаемого чайника Homo Sapiens'a | Конечное изображение того же чайника |
После этого программа как обычно берет пиксели из картинки, переводит их в градации серого, сравнивает полученный цвет со средним и делает вывод - какого цвета рисовать точку - белого или черного.
Шумоподавление нужно, прежде всего, для тех фотографий, где качество оставляет желать лучшего. Например, у нас есть фотка, где много-много белых точек и царапин (ну, посыпали на нее вначале алмазной крошкой, а потом еще и растерли). Программа, распознающая глаз, может затрудниться найти этот самый глаз среди множества 'левых' точек. Пример программы вы можете посмотреть в программном отчете 'Final Release (ObraZ project)'. Например, был придуман алгоритм, который "распространяет" шумы в некоторой окрестности. Сначала хотели использовать шаблоны окрестностей. Каждый шаблон либо является критерием шума, либо критерием "правильной" окрестностью. Но позже было обнаружено, что невозможно подобрать такие шаблоны, потому что некоторые из них будут в некоторых случаях являться шумами, в некоторых -нет, поэтому мы решили придумать такой алгоритм, который будет "равноправно" удалять шумы (попутно округлять некоторые части образов на картинке). То есть изменение цвета клетки зависит только от количества черного и белого цвета в данной окрестности и совсем не зависит от их расположения в окрестности. Если брать окрестность 2*2 пикселя, то непонятно, что делать, когда две клетки черные, а две - белые. Кому отдать приоритет? Можно, конечно, посчитать количество белых и черных клеток на картинке и отдать предпочтение большему. Но все же даже после такого подсчета остается непонятным, какой цвет является цветом фона, а какой - цветом изображения. Так что, чтобы не мучаться, мы решили взять окрестность 3*3. Чтобы не нарушать симметрию, красить не верхний левый угол, а центральную клетку. Если черных больше 4, то в черный, иначе в белый - все просто!
А теперь представьте себе, что есть черно-белая фотка, на которой отчетливо видны все черты лица, но при ближайшем рассмотрении видно, что эти черты прорисованы не сплошной линией, а отдельно стоящими точками. Таким образом, программа распознавания глаза не сможет правильно определить расположение глаза (точнее, зрачка). А программа размытия сможет соединить точки в одну линию, что упростит задачу распознавания.
Special Thanks to all people agreed to provide us their photos and eyes. They were:
Березин Андрей Всеволодович, Кореец Раритетный, Иван Сергеевич Неретин, Данила Гончаров, Люда Петрова, ЧайникHomo Sapiens'a (provided by some local museum) and other.

После некоторого количества времени, проведённого в тщетных попытках штурмовать главную задачу проекта кодированием фильтров и разложений на два или четыре цвета и набив приличную кипу проблем и невыспанную физиономию, мы наконец были посажены нашими преподами за стол переговоров. Нам внятно объяснили, что хватит заниматься не особо существенными вещами и пора переходить на продвинутые системы опознавания, т.е. системы образов.
После n-ого количества провокационных вопросов из нас вытрясли, что опознавать лучше по глазу (точнее, по радужной оболочке и зрачку). Был приведён ряд убедительных фактов по этому поводу.
Глаз является самым удобным для опознания, потому что:
1. Зрачок имеет форму круга (почти), т.е. является, похоже, единственной частью лица с правильной геометрической формой.
2. Он находится на белом (или почти белом) фоне, что облегчит поиск.
3. Он имеет небольшие размеры, что ускорит поиск.
4. Он уникален для каждого человека
Но встаёт естественный вопрос - как искать?
Установилась следующая модель:
1. Вырезается область глаз.
4. Полученная картинка упрощается до двух цветов.
5. Двухцветная картинка раскладывается на области, т.е. глаз и ненужный остаток; среди полученных областей находим область глаза и координаты всех её пикселей.
6. Выделяем по полученным координатам глаз на оригинальном изображении.
7. Сравниваем попиксельно получившиеся глаза.
Рассмотрим алгоритмы, применяющиеся для осуществления этих пунктов.
1. Область глаза вырезается просто и тупо - берётся центральная часть фотографии. Понятно, что если на фотографии верхней границей лица является нос, то ничего не выйдет.
2. Алгоритм упрощения до двух цветов - это отдельная, довольно большая тема. Она раскрыта в статье "Метод кластеров".
3. Этот пункт самый интересный. Мы знаем, что двухцветная картинка содержит глаз в форме круга. Это главное; что там ещё получится, нам не важно. Итак, нужно опознать чёрно-белый круг на фоне "помех". Для этого мы используем алгоритм, распознающий чёрные области.
Рекурсивный алгоритм разметки областей:
Он основывается на дискретном представлении компьютером изображений. Принцип следующий: сканируем картинку, когда мы находим черную точку, проверяем, есть ли на ней "метка", означающая, что эту точку уже "обработали" (не буду затрагивать реализацию меток). Если она есть, то сканируем дальше, если её нет, то запускается рекурсивная функция, которой передаются координаты пикселя, на котором её вызвали. Функция сканирует прилегающие к её координатам пиксели, если находит чёрные, то запускает себя с их координатами, метит "материнский" пиксель. Таким образом, вся чёрная фигура, неразумно попавшаяся под наш скан, становится меченой. Так что метки для каждой области свои.
Мы получили области. Пусть они отличаются, например, цветом (а на самом деле пиксели, относящиеся к одной области, в массиве имеют свой порядковый номер). Круг можно выделить по соотношению его периметра и площади, являющемуся константой для всех кругов. Так как у нас есть все координаты его точек, то подсчитать и то и другое не составит проблем.
4. Координаты есть - какие проблемы?
5. Сравниваются цвета пикселей двух разных глаз.
Теперь спустимся обратно на землю и поищем какие-нибудь недочёты в предыдущем алгоритме. Главная проблема заключается в том, что обычно радужная оболочка со зрачком частично закрываться веками и, как следствие, при переводе в два цвета может просто слиться с ними.
Понятно, что выше указанный алгоритм с таким глазом работать не будет.
В таком случае выделять и работать придётся с обрезком глаза. Для выделения такого зрачка был придуман новый алгоритм.
На изображении находятся переходы из белого цвета в чёрный и наоборот (так называемые точки перехода). Заметим, что если мы будем искать их по горизонталям (сканировать по горизонтали), то при прохождении зрачка мы получим четыре перехода, по два каждого вида. Соответственно мы можем найти точки перехода зрачка. Будем считать переходы каждого вида; тогда переходом зрачка будет является каждый первый бело-чёрный переход и каждый второй чёрно-белый. Естественно, что это относится только к горизонталям с четырьмя точками перехода.
Для точности найдём все точки перехода зрачка, лежащие на горизонталях с четырьмя переходами и найдём центры с радиусами n-ого количества окружностей. Так как всегда можно построить окружность по трем точкам, не лежащим на одной прямой, мы можем брать любые тройки из "внутренних" точек перехода (относящихся к зрачку). Но проблема в том, что большая погрешность получается в том случае, когда мы берем три точки с одной стороны зрачка (либо с правой, либо с левой). Поэтому надо бы как-нибудь придумать алгоритм "выбирания" двух точек с одной стороны и одной - с другой. Но в этом нет никакой проблемы. Сканируя изображение, мы заносим в массив размеченные пиксели как раз с чередованием сторон. Потом возьмём среднее значение от полученных результатов.
Теперь найдём координаты центра зрачка и его радиус.
Осталось только вырезать.
Этим алгоритмом можно выделять зрачки наклонённых глаз (где-то до 30-45 градусов в зависимости от степени "заслонения" веком зрачка), т.е. пока есть хотя бы две горизонтали с четырьмя переходами на каждой.
Если хочется работать с ну очень кривыми (наклонёнными) глазами, то можно приписать к коду кусок, умеющий определять точку перехода зрачка в горизонтали с 3-,2- переходами. Или же можно сканировать глаз и, если очень мало горизонталей с четырьмя точками перехода, поворачивать глаз на некоторый угол. Это ест куда больше времени и усилий, да и для нормальных фотографий не нужно.
Теперь начинается самое весёлое. Для НАСТОЯЩИХ глаз вышеуказанный метод НЕ РАБОТАЕТ, т.к. на них слишком много шумов. Чем, собственно, и следует заняться в будущем.
Special Thanks to: Андрею Суровцеву-Бутову, любезно предоставившему свой глаз для использования его в качестве материала наших эксперимента.